Lecture 1, Introduction and Word Vectors
What do we hope to learn?
-
RNN
-
Attention
-
PyTorch
-
Word meaning, dependency parsing, machine translation, question answering
Traditional NLP use one-hot encoding for words. The problem is that the one-hot matrix can be very big. There is no natural notion of similarity of one-hot vectors because they are orthogonal.
We can use a word similarity tabl, yet the table will be very large (500,000 words X 500,000 words)!
Denotational Semantics VS. Distributional Semantics
-
Denotational Semantics: signifier (symbol) ⟺ signified (idea or thing)
-
Distributional Semantics: A word’s meaning is given by the words that frequently appear close-by
Word2vec
Idea:
-
We have a large corpus of text
-
Every word in a fixed vocabulary is represented by a vector
-
Go through each position t in the text, which has a center word c and context (“outside”) words o
-
Use the similarity of the word vectors for c and o to calculate the probability of o given c (or vice versa)
-
Keep adjusting the word vectors to maximize this probability
Example windows and process for computing \({P(w_{t+j} | w_t)}\)
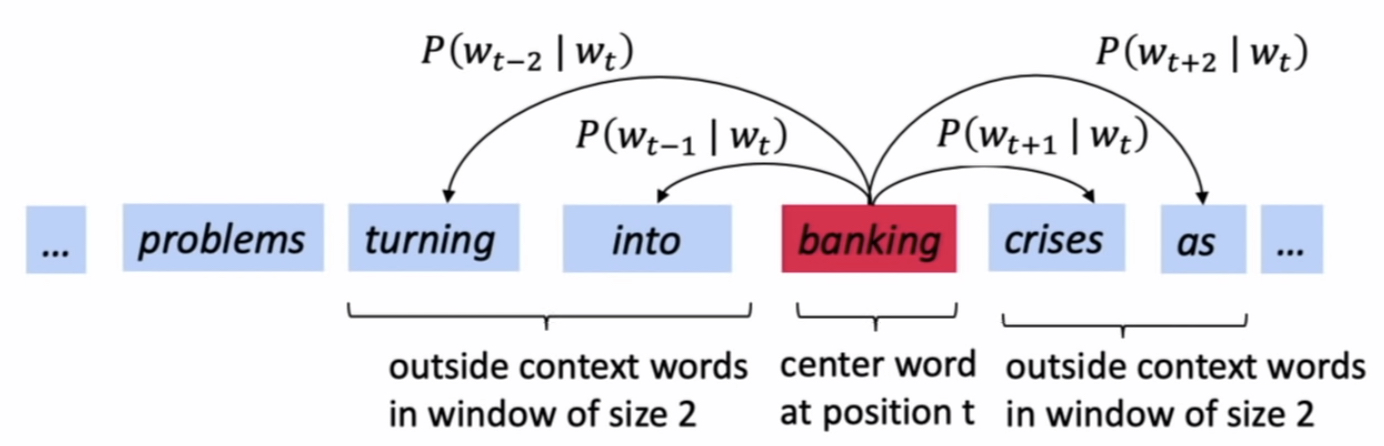
We want to maximize the overall log likelihood of getting a correct prediction of context words within a window of fixed size m given center word \(w_j\). The objective function is:
\[Likelihood = L(\theta)=\prod_{t=1}^{T} \prod_{-m \leq j \leq m \atop j \neq 0} P\left(w_{t+j} | w_{t} ; \theta\right)\]Then the objective function is the average negative log likelihood.
\[{ J(\theta)=-\frac{1}{T} \log L(\theta)=-\frac{1}{T} \sum_{t=1}^{T} \sum_{-m \leq j \leq m \atop j \neq 0} \log P\left(w_{t+j} | w_{t} ; \theta\right) }\]Question: How to calculate \({P(w_{t+j} | w_t)}\) ?
Answer: Use two vectors per word \(w\)
-
\(v_w\) when w is center word
-
\(u_w\) when w is a context word
Then for a center word c and a context word o:
\[P(o | c)=\frac{\exp \left(u_{o}^{T} v_{c}\right)}{\sum_{w \in V} \exp \left(u_{w}^{T} v_{c}\right)}\]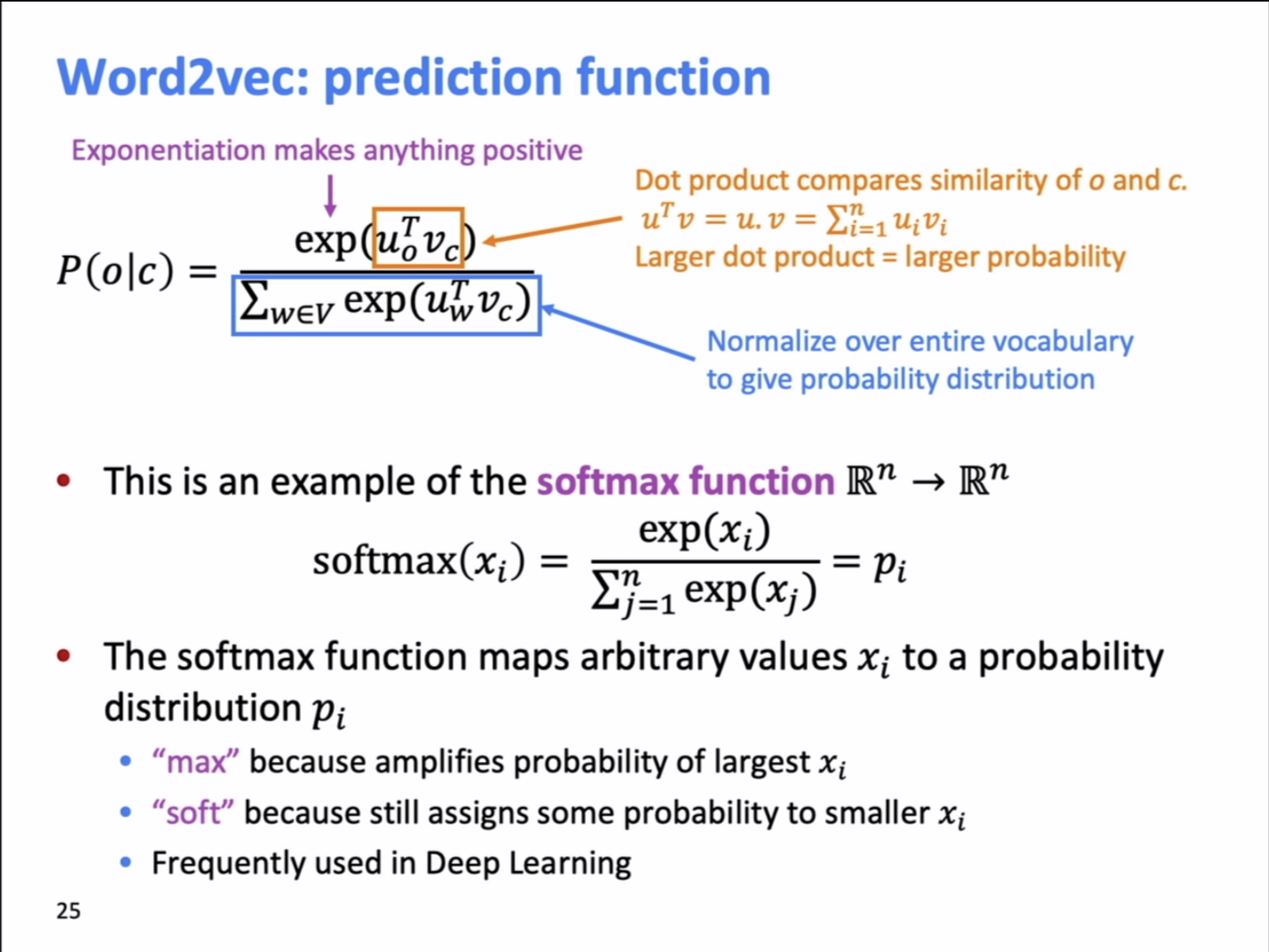
HW1
Got problem using virtual environment. The nltk can not find reuters. Deactivate virtual environment solved this. Link to HW1
Lecture 2, Word Vectors and Word Senses
idf-weighting
Lecture 5, Dependency Parsing
After two lectures of mathematical background in deep learning, we can finally started to learn some NLP stuff.
1. Two views of linguistic structure:
Phrase structure: organizes words into nested constituents.
- Can represent the grammar with CFG rules
Constituency = phrase structure grammar = context-free grammars (CFGs)
NP: noun phrase
PP: preposition
Det: Determinant
- Some of the grammar rules
- NP -> Det N (the cat, a dog)
- NP -> Det (Adj) N
- NP -> Det(Adj) N PP
- PP -> PP NP
Dependency structure
- Dependency structure shows which words depend on (modify or are arguments of ) which other words.
Why do we need sentence structure? We, human, need a certain sentence structure in order to convey complex meaning.
Example of prepositional phrase attachment ambiguity
This is an example of why NLP is hard. We human are communicate through languages, but language alone will not do it. We talk to people with the assumption that the other person have similar knowledge as ourself. This is “Common Sense”.
Here is an example of ambiguous sentences: San Jose cops kill man with knife
There are two meaning for this one sentences. First, cops stabbed and killed a man using knife. Second, cops killed a man who is holding a knife. According to our common sense, we tend to believe that the second is true. The meaning of a sentence is depended on the dependency structure of words. This is also why human languages are very different from programming languages.
- Catalan numbers: ${ C_n = (2n)! / [(n+1)!n!]}$
- An exponentially growing series, which arises in many tree-like contexts. CS228: Prob. Graphic Model.
Coordination Scope Ambiguity
Shuttle veteran and longtime NASA executive Fred Gregory appointed to board.
Either Fred Gregory is a shuttle veteran and a longtime NASA executive, or two people where one is shuttle veteran and the other is NASA executive.
Adjectival Modifier Ambiguity
This is a graduate level class, so prof. actually showed this example in his lecture!!!
Student get first hand job experience
Verb Phrase (VP) attachment ambiguity
The rise of annotated data, Universal Dependencies Treebands
Build a tree band seems a lot slower and less useful than building a grammar. But treebank have following advantages:
- Reusability of the labor
- Many parsers, part-of-speech taggers, etc. can be build on it
- Valuable resource for linguistics
- Broad coverage, not just a few intuitions
- Frequencies and distributional information
- A way to evaluate systems
Dependency can cross over: I will give a talk tomorrow on bootstrapping
on bootstrapping cross over talk.
Lecture 7, Vanishing Gradients, Fancy RNNs
Topics: Vanishing (exploding) gradient, LSTM, GRU, bidirectional, Multi-layers